Resources for the second edition are here. I'd love to know what you think about Python Crash Course; please consider taking a brief survey. If you'd like to know when additional resources are available, you can sign up for email notifications here.
Solutions - Chapter 16
- 16-2: Sitka-Death Valley Comparison
- 16-3: Rainfall
- 16-4: Explore
- 16-6: Gross Domestic Product
- 16-8: Testing the
country_codesModule
Back to solutions.
16-2: Sitka-Death Valley Comparison
The temperature scales on the Sitka and Death Valley graphs reflect the different ranges of the data. To accurately compare the temperature range in Sitka to that of Death Valley, you need identical scales on the y-axis. Change the settings for the y-axis on one or both of the charts in Figures 16-5 and 16-6, and make a direct comparison between temperature ranges in Sitka and Death Valley (or any two places you want to compare). You can also try plotting the two data sets on the same chart.
The pyplot function ylim() allows you to set the limits of just the y-axis. If you ever need to specify the limits of the x-axis, there’s a corresponding xlim() function as well.
import csv
from datetime import datetime
from matplotlib import pyplot as plt
# Get dates, high, and low temperatures from file.
filename = 'sitka_weather_2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
dates, highs, lows = [], [], []
for row in reader:
try:
current_date = datetime.strptime(row[0], "%Y-%m-%d")
high = int(row[1])
low = int(row[3])
except ValueError:
print(current_date, 'missing data')
else:
dates.append(current_date)
highs.append(high)
lows.append(low)
# Plot data.
fig = plt.figure(dpi=128, figsize=(10, 6))
plt.plot(dates, highs, c='red', alpha=0.5)
plt.plot(dates, lows, c='blue', alpha=0.5)
plt.fill_between(dates, highs, lows, facecolor='blue', alpha=0.1)
# Format plot.
title = "Daily high and low temperatures - 2014\nSitka, AK"
plt.title(title, fontsize=20)
plt.xlabel('', fontsize=16)
fig.autofmt_xdate()
plt.ylabel("Temperature (F)", fontsize=16)
plt.tick_params(axis='both', which='major', labelsize=16)
plt.ylim(10, 120)
plt.show()
Output:
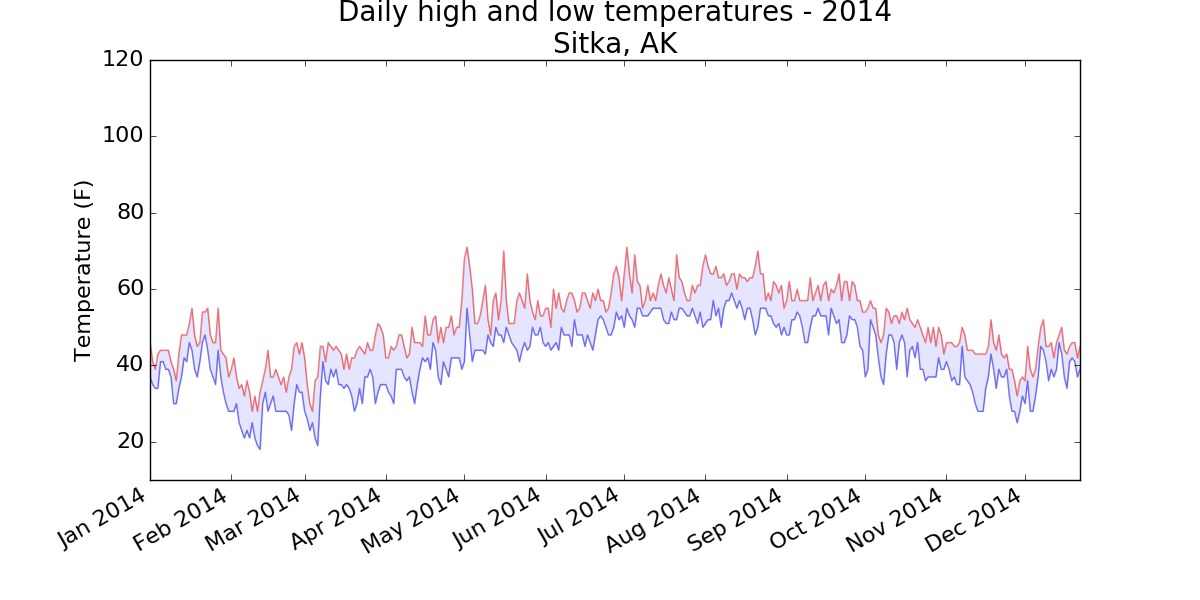
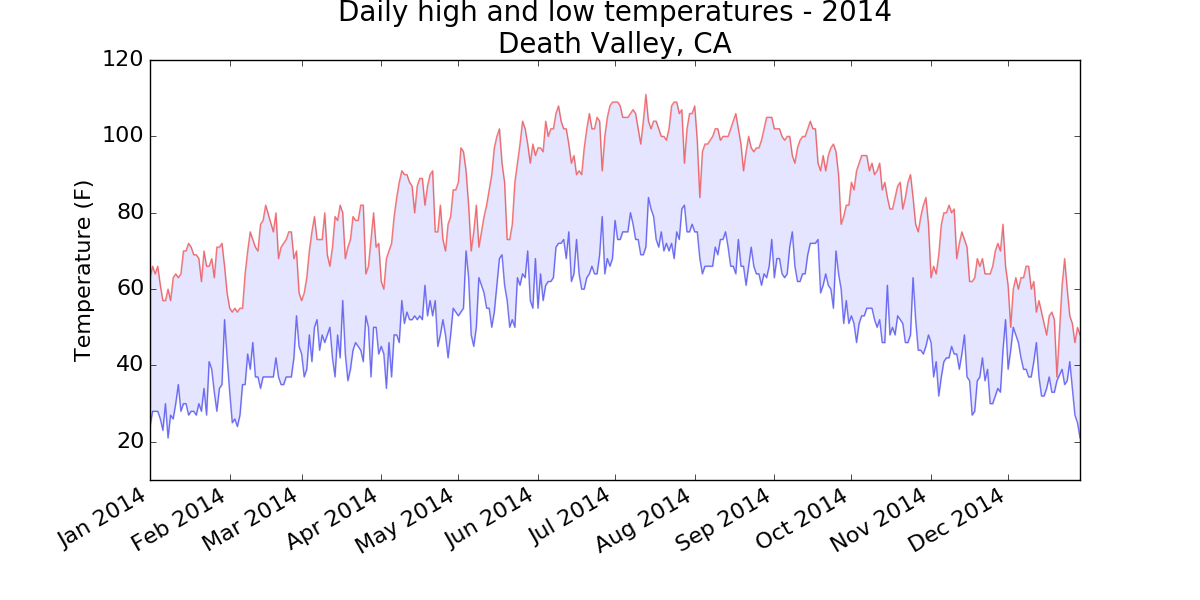
Using the same limits for the ylim() function with the Death Valley data results in a chart that has the same scale:
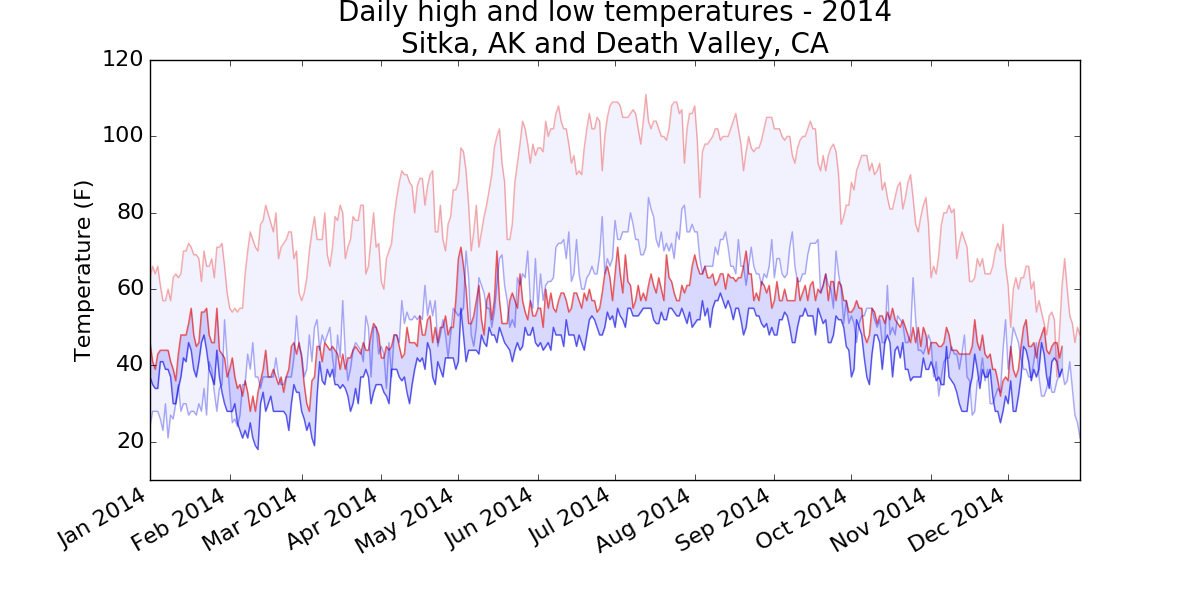
There are a number of ways you can approach plotting both data sets on the same chart. In the following solution, we put the code for reading the csv file into a function. We then call it once to grab the highs and lows for Sitka before making the chart, and then call the function a second time to add Death Valley’s data to the existing plot. The colors have been adjusted slightly to make each location’s data distinct.
import csv
from datetime import datetime
from matplotlib import pyplot as plt
def get_weather_data(filename, dates, highs, lows):
"""Get the highs and lows from a data file."""
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
# dates, highs, lows = [], [], []
for row in reader:
try:
current_date = datetime.strptime(row[0], "%Y-%m-%d")
high = int(row[1])
low = int(row[3])
except ValueError:
print(current_date, 'missing data')
else:
dates.append(current_date)
highs.append(high)
lows.append(low)
# Get weather data for Sitka.
dates, highs, lows = [], [], []
get_weather_data('sitka_weather_2014.csv', dates, highs, lows)
# Plot Sitka weather data.
fig = plt.figure(dpi=128, figsize=(10, 6))
plt.plot(dates, highs, c='red', alpha=0.6)
plt.plot(dates, lows, c='blue', alpha=0.6)
plt.fill_between(dates, highs, lows, facecolor='blue', alpha=0.15)
# Get Death Valley data.
dates, highs, lows = [], [], []
get_weather_data('death_valley_2014.csv', dates, highs, lows)
# Add Death Valley data to current plot.
plt.plot(dates, highs, c='red', alpha=0.3)
plt.plot(dates, lows, c='blue', alpha=0.3)
plt.fill_between(dates, highs, lows, facecolor='blue', alpha=0.05)
# Format plot.
title = "Daily high and low temperatures - 2014"
title += "\nSitka, AK and Death Valley, CA"
plt.title(title, fontsize=20)
plt.xlabel('', fontsize=16)
fig.autofmt_xdate()
plt.ylabel("Temperature (F)", fontsize=16)
plt.tick_params(axis='both', which='major', labelsize=16)
plt.ylim(10, 120)
plt.show()
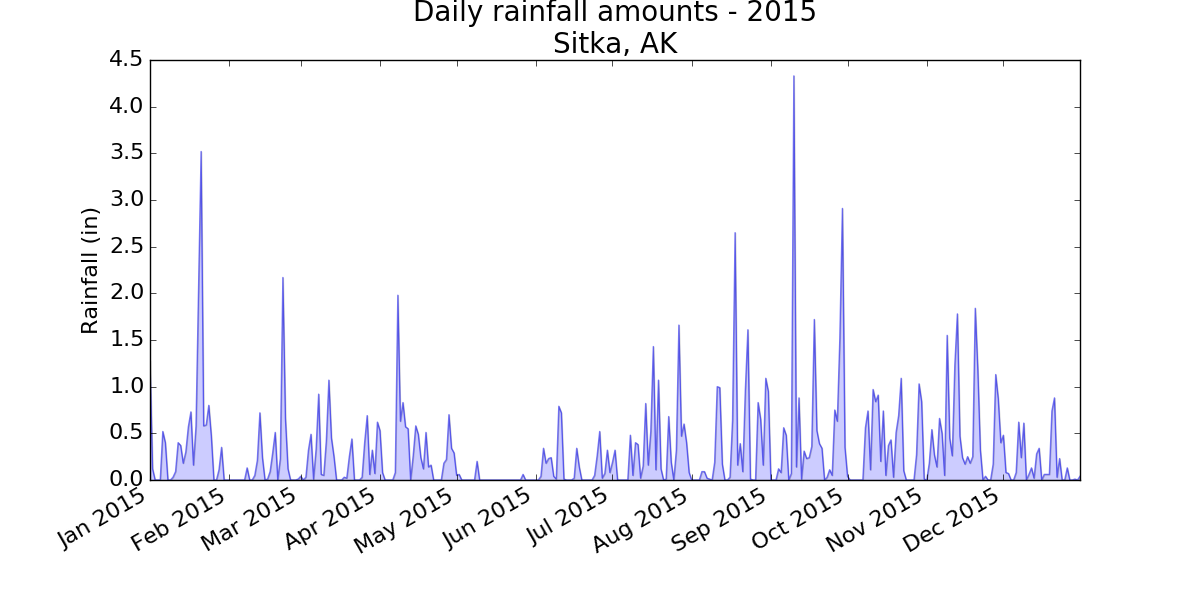
16-3: Rainfall
Choose any location you’re interested in, and make a visualization that plots its rainfall. Start by focusing on one month’s data, and then once your code is working, run it for a full year’s data.
Note: You can find the data file for this example here.
import csv
from datetime import datetime
from matplotlib import pyplot as plt
# Get dates and rainfall data from data file.
# Rainfall data is in column 19.
filename = 'sitka_rainfall_2015.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
dates, rainfalls = [], []
for row in reader:
try:
current_date = datetime.strptime(row[0], "%Y-%m-%d")
rainfall = float(row[19])
except ValueError:
print(current_date, 'missing data')
else:
dates.append(current_date)
rainfalls.append(rainfall)
# Plot data.
fig = plt.figure(dpi=128, figsize=(10, 6))
plt.plot(dates, rainfalls, c='blue', alpha=0.5)
plt.fill_between(dates, rainfalls, facecolor='blue', alpha=0.2)
# Format plot.
title = "Daily rainfall amounts - 2015\nSitka, AK"
plt.title(title, fontsize=20)
plt.xlabel('', fontsize=16)
fig.autofmt_xdate()
plt.ylabel("Rainfall (in)", fontsize=16)
plt.tick_params(axis='both', which='major', labelsize=16)
plt.show()
Output:
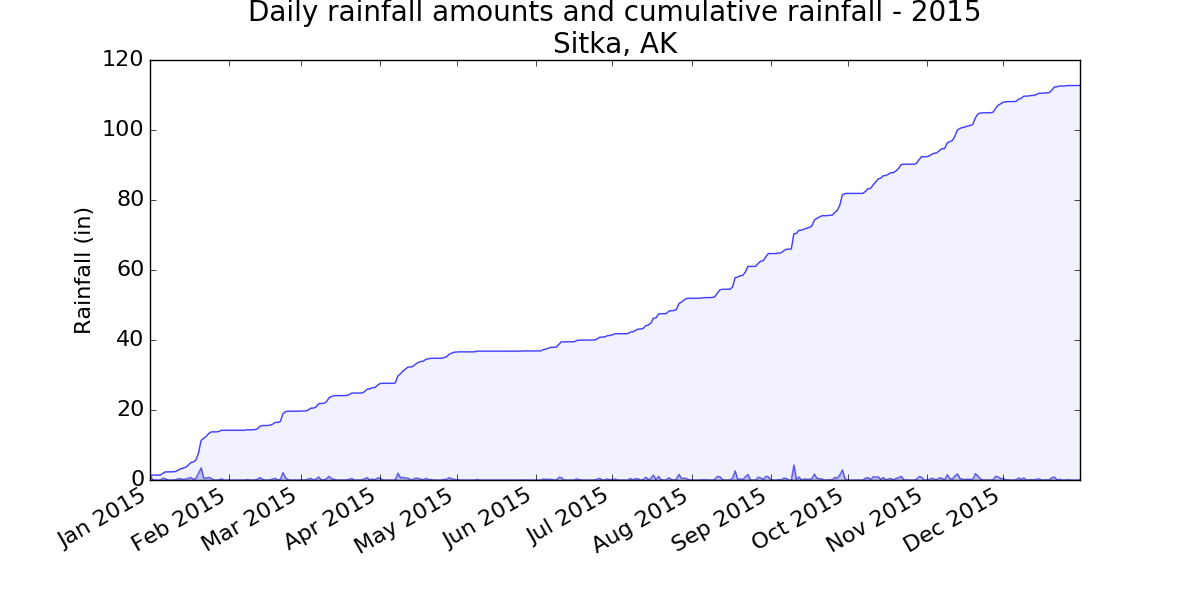
16-4: Explore
Generate a few more visualizations that examine any other weather aspect you’re interested in for any locations you’re curious about.
I live in a rainforest, so I was interested in playing with the rainfall data. I calculated the cumulative rainfall for the year, and plotted that over the daily rainfall. Even after living in this rain, I’m surprised to see how much we get.
import csv
from datetime import datetime
from matplotlib import pyplot as plt
# Get dates and rainfall data from data file.
# Rainfall data is in column 19.
filename = 'sitka_rainfall_2015.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
dates, rainfalls, totals = [], [], []
for row in reader:
try:
current_date = datetime.strptime(row[0], "%Y-%m-%d")
rainfall = float(row[19])
except ValueError:
print(current_date, 'missing data')
else:
dates.append(current_date)
rainfalls.append(rainfall)
if totals:
totals.append(totals[-1] + rainfall)
else:
totals.append(rainfall)
# Plot data.
fig = plt.figure(dpi=128, figsize=(10, 6))
plt.plot(dates, rainfalls, c='blue', alpha=0.5)
plt.fill_between(dates, rainfalls, facecolor='blue', alpha=0.2)
plt.plot(dates, totals, c='blue', alpha=0.75)
plt.fill_between(dates, totals, facecolor='blue', alpha=0.05)
# Format plot.
title = "Daily rainfall amounts and cumulative rainfall - 2015\nSitka, AK"
plt.title(title, fontsize=20)
plt.xlabel('', fontsize=16)
fig.autofmt_xdate()
plt.ylabel("Rainfall (in)", fontsize=16)
plt.tick_params(axis='both', which='major', labelsize=16)
plt.show()
Output:
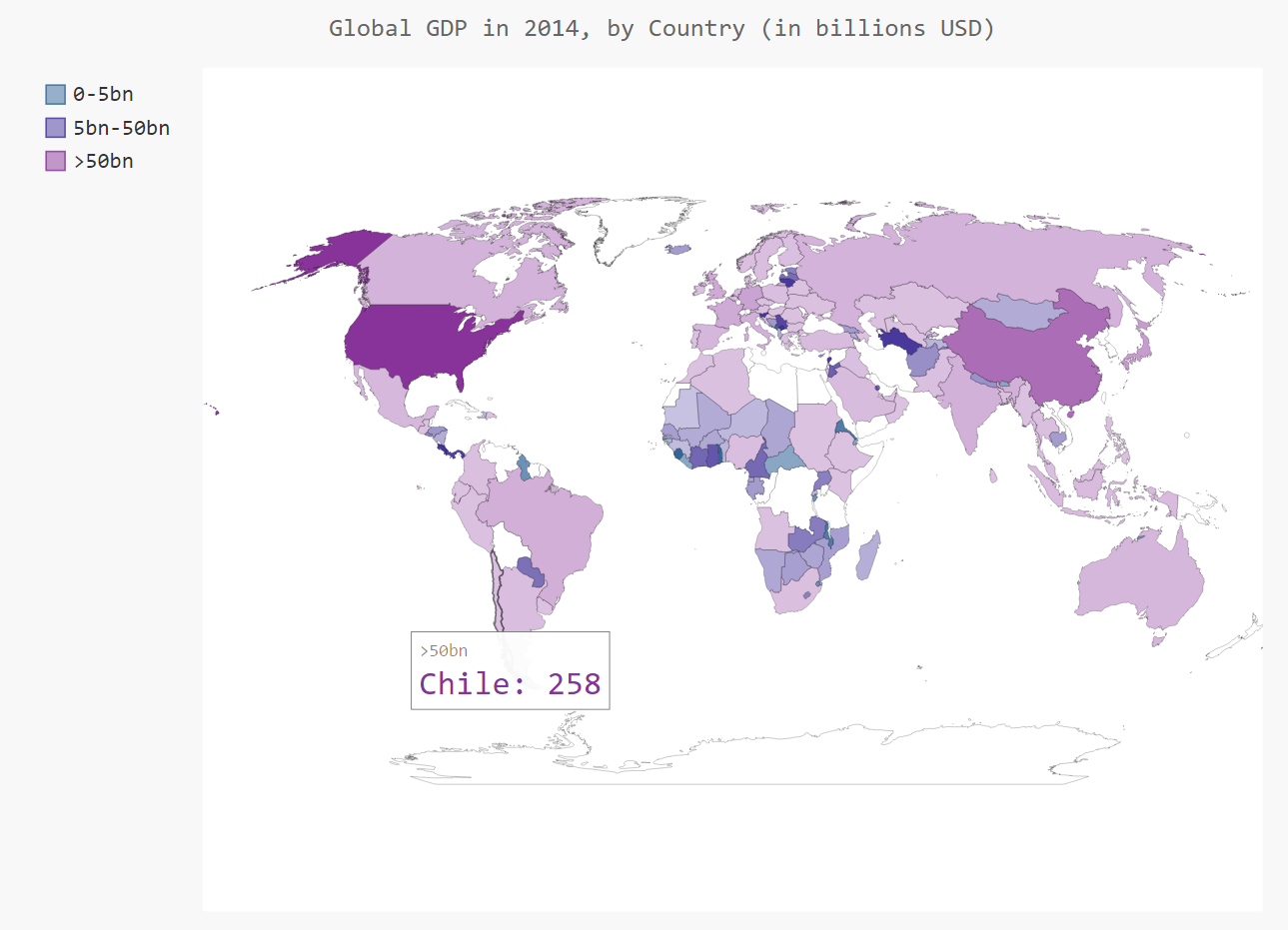
16-6: Gross Domestic Product
The Open Knowledge Foundation maintains a data set containing the gross domestic product (GDP) for each country in the world, which you can find at http://data.okfn.org/data/core/gdp/. Download the JSON version of this data set, and plot the GDP of each country in the world for the most recent year in the data set.
Note: If you’re having trouble downloading the JSON file for GDP data, you can try this direct link. If that still doesn’t work, I’ve stored a copy of the file here.
*Note: Be aware that some versions of this data file have years in quotes, and some have the years unquoted. When the years are quoted they’re treated as strings. When they’re unquoted they’re treated as numerical data. You may need to change comparisons like if gdp_dict['Year'] == '2014' to if gdp_dict['Year'] == 2014:.
Note: The newest version of Pygal handles world maps in a slightly different way than what was described in the book. If you haven’t seen it already, take a look at the updates for Chapter 16.
import json
import pygal
from pygal.style import LightColorizedStyle as LCS, RotateStyle as RS
from pygal.maps.world import World
from country_codes import get_country_code
# Load the data into a list.
filename = 'global_gdp.json'
with open(filename) as f:
gdp_data = json.load(f)
# Build a dictionary of gdp data.
cc_gdps = {}
for gdp_dict in gdp_data:
if gdp_dict['Year'] == '2014':
country_name = gdp_dict['Country Name']
gdp = int(float(gdp_dict['Value']))
code = get_country_code(country_name)
if code:
cc_gdps[code] = gdp
# Group the countries into 3 gdp levels.
# Less than 5 billion, less than 50 billion, >= 50 billion.
# Also, convert to billions for displaying values.
cc_gdps_1, cc_gdps_2, cc_gdps_3 = {}, {}, {}
for cc, gdp in cc_gdps.items():
if gdp < 5000000000:
cc_gdps_1[cc] = round(gdp / 1000000000)
elif gdp < 50000000000:
cc_gdps_2[cc] = round(gdp / 1000000000)
else:
cc_gdps_3[cc] = round(gdp / 1000000000)
# See how many countries are in each level.
print(len(cc_gdps_1), len(cc_gdps_2), len(cc_gdps_3))
wm_style = RS('#336699', base_style=LCS)
wm = World(style=wm_style)
wm.title = 'Global GDP in 2014, by Country (in billions USD)'
wm.add('0-5bn', cc_gdps_1)
wm.add('5bn-50bn', cc_gdps_2)
wm.add('>50bn', cc_gdps_3)
wm.render_to_file('global_gdp.svg')
Output:
16-8: Testing the country_codes Module
When we wrote the country_codes module, we used print statements to check whether the get_country_code() function worked. Write a proper test for this function using what you learned in Chapter 11.
import unittest
from country_codes import get_country_code
class CountryCodesTestCase(unittest.TestCase):
"""Tests for country_codes.py."""
def test_get_country_code(self):
country_code = get_country_code('Andorra')
self.assertEqual(country_code, 'ad')
country_code = get_country_code('United Arab Emirates')
self.assertEqual(country_code, 'ae')
country_code = get_country_code('Afghanistan')
self.assertEqual(country_code, 'af')
unittest.main()
Output:
.
----------------------------------------------------------------------
Ran 1 test in 0.000s
OK